Over 15k researchers choose OmicsBox for their projects!
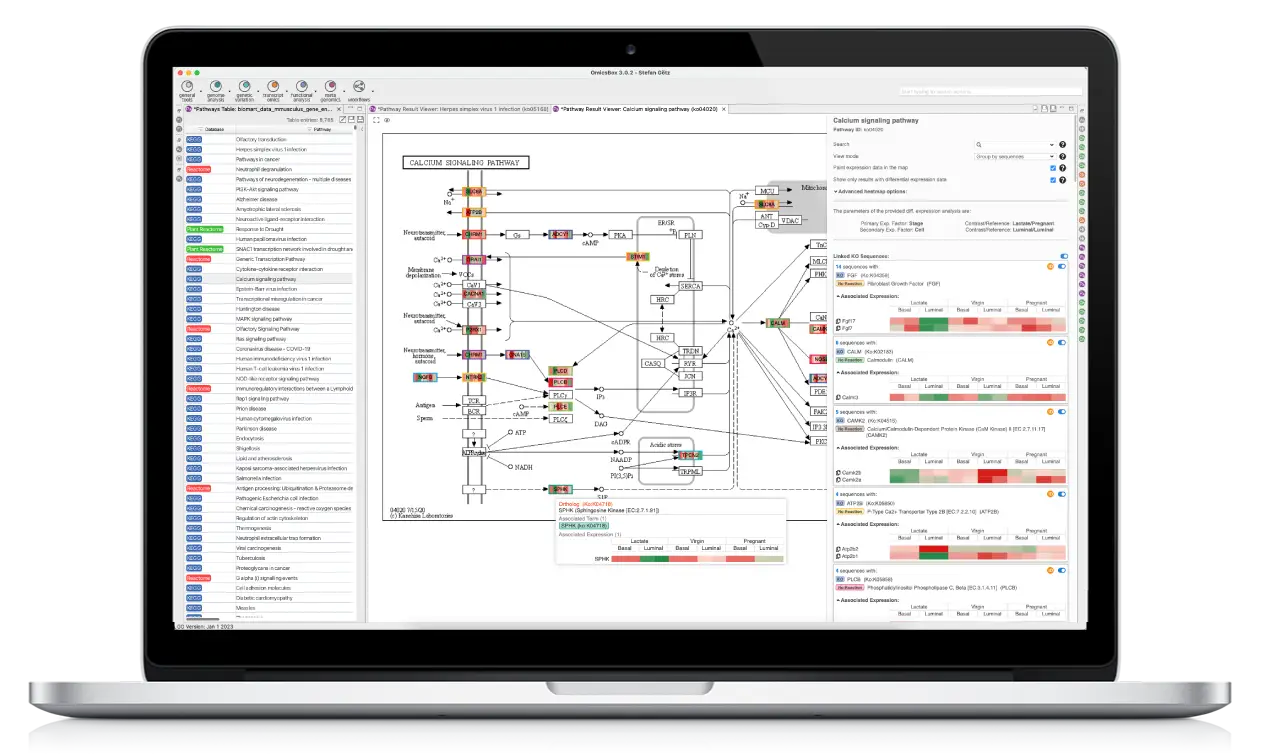
OmicsBox is the leading bioinformatics solution that offers end-to-end NGS data analysis of genomes, transcriptomes, and metagenomes.
We have designed OmicsBox to be user-friendly, efficient, and with a powerful set of tools to extract biological insights from omics data.
OmicsBox is used by top private and public research institutions worldwide. It allows researchers to easily process large and complex data sets, and streamline their analysis process.
BioBam is a leading bioinformatics solution provider which accelerates research in disciplines such as agricultural genomics, microbiology, and environmental NGS studies, amongst others.
At BioBam we are committed to the development of user-friendly software solutions for biological research. Our mission is to transform complex data analysis procedures into attractive and interactive tasks. Our ultimate goal is to close the gap between experimental work, bioinformatics analysis, and applied research.